GOV.UK Site search: How it works
Overview
The core functionality of the site search stack consists of three main parts:
- Synchronisation (sometimes called “indexing”): Continuous ingestion of data from the GOV.UK content ecosystem (via Publishing API), extracting relevant content and metadata, and storing it in Google Vertex AI Search
- Querying: Providing an API that acts as a translation layer between Finder Frontend and Google Vertex AI Search, executing search queries with optional filters, and transforming results into the expected data format for display to the user
- Analytics pipeline: Daily ingestion of user interaction data from GA4 used by Vertex AI Search to improve the ranking model.
Explainer: Google product names
We use Vertex AI Search (VAIS, “Vertex” for short) to describe the search product we use.
During the lifetime of our implementation project, this search product has been renamed several times (starting off as “Gen AI App Builder: Enterprise Search”, then “Vertex AI Search and Conversation”, now just “Vertex AI Search”) and now comes under the umbrella of (Vertex AI) Agent Builder as part of Google’s overall Vertex AI brand for all things AI. It’s not to be confused with the plain Vertex AI product though (their overall AI development platform which provides access to Gemini LLMs).
Discovery Engine is the name of the API used by integrations with VAIS, which is partly shared with a similar-but-different product named Cloud Retail Search (CRS). In the code and code-adjacent documentation, we prefer to use Discovery Engine naming over VAIS where possible to future proof ourselves for the next product renaming.
Architecture
Architecture summary
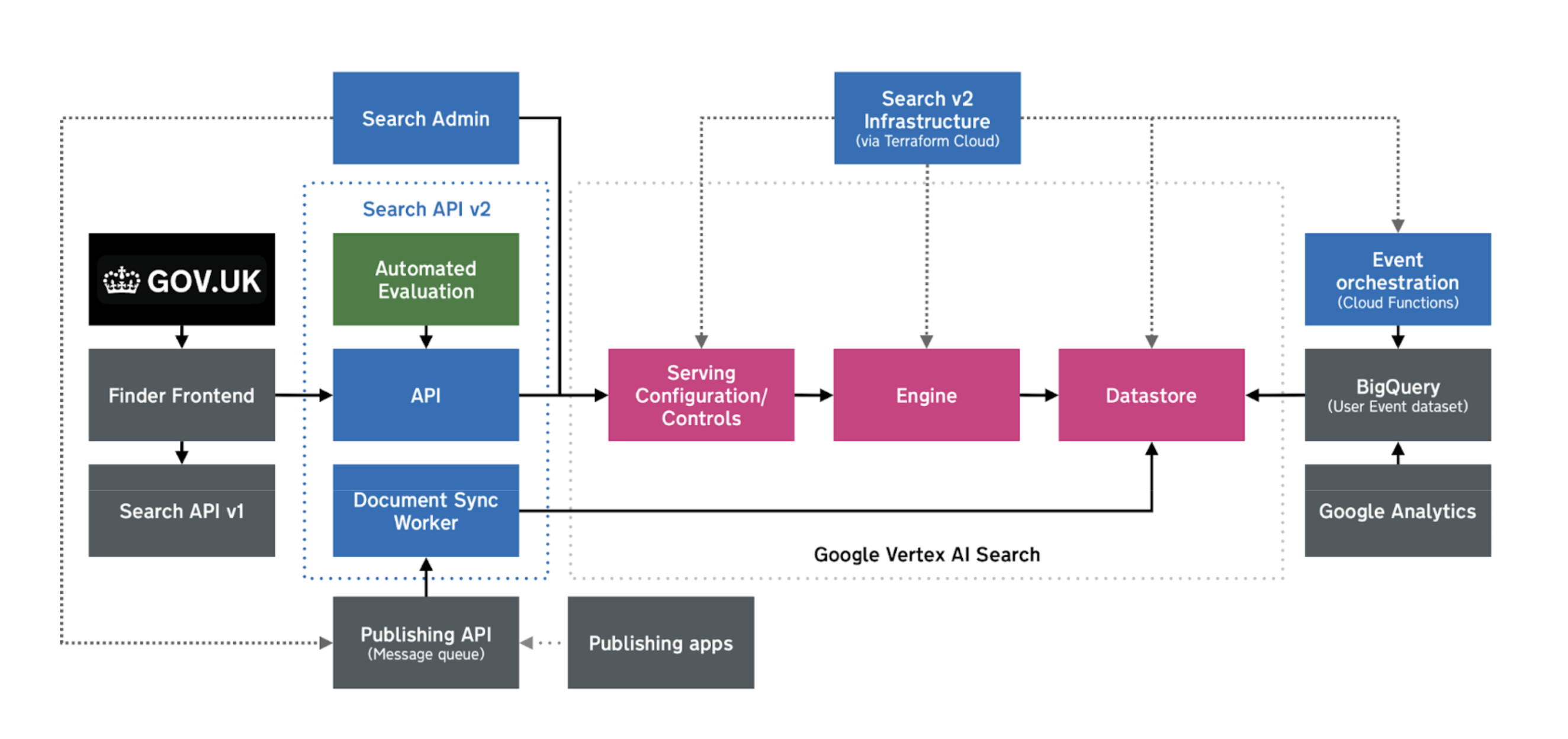
Broadly, the new search stack for site search introduces the following new components to the GOV.UK technical ecosystem:
A deployment of Vertex AI Search (VAIS) in Google Cloud Platform (GCP) managed by Terraform, comprising per-environment GCP projects with a datastore (and schema), an engine, and serving configuration and controls
Search API v2: A Ruby on Rails application deployed on the standard GOV.UK AWS Kubernetes infrastructure, providing an API for querying (search and autocomplete) the VAIS serving configuration, a synchronisation module for updating the state of the VAIS datastore, and a scheduled task performing ongoing automated relevance evaluations.
User event data pipeline: BigQuery tables of GA4 user interaction data that are populated via a dataform pipeline, and used by Vertex to train the model serving relevant search results.
The new search stack has a direct dependency on the following existing projects:
Finder Frontend: to display results to users (modified by us to be able to call either the legacy Search API or Search API v2)
Search Admin: Formerly used to configure the legacy search stack, this has been cleaned up to remove legacy functionality but is still used to publish external links (a content type only used in search on GOV.UK) and will be extended in the future to allow configuration of VAIS without requiring developer input
Publishing API: to receive event messages over the publishing message queue (AWS managed RabbitMQ). Note that unlike Search API, there are no direct API calls from or to Whitehall, all content changes go through the MQ
Core data flows
When a content item is published by GOV.UK content editors
The publishing application pushes the content change to Publishing API
Publishing API processes the content change and pushes an update message to its RabbitMQ message queue
Search API v2’s synchronisation worker picks up a change message, acquires a lock on the content ID, extracts content and metadata from the content item based on a set of rules (data paths), and updates the document in VAIS
When a user performs a search
As the user types, autocomplete suggestions are offered by the Search with autocomplete GOV.UK Publishing Components component, through a public proxy endpoint on Finder Frontend that calls the underlying feature on Search API v2
When the user submits a search request, it is processed by Finder Frontend, which constructs a search query to Search API v2 (according to the same API contract as the legacy Search API)
Search API v2 receives the query, applies some query-time boosts to it and translates it to a VAIS API call, then maps the API response back to the format expected by Finder Frontend
Finder Frontend renders the results, together with a VAIS attribution token that is tracked by the analytics code
Google Analytics (GA4) tracks how the user interacts with results
GA4 data is processed overnight by the existing GOV.UK analytics pipeline, and ingested into GCP BigQuery.
Three times a day, the GA4 data is imported and pushed into VAIS as user events. VAIS adjusts the internal ranking model for the engine based on these user events (and some data from its own proprietary search and internet analytics data)
Infrastructure
Deployment & environments
The new search stack follows the same environment conventions as other GOV.UK applications, having integration, staging, and production environments. Our GCP account has separate projects for each environment with fully isolated resources.
The Search API v2 application is deployed as a standard GOV.UK application on the Kubernetes platform, following all the usual conventions.
As a SaaS product, it isn’t possible to run Vertex locally. We previously had a separate “dev” environment in GCP with Vertex resources provisioned for each active developer on the team, but the extra complexity and manual overrides didn’t feel worth it (especially since the bulk of requirements for local use revolved around read access). We now point local development environments for Search API v2 at integration.
Infrastructure as code (IaC)
All infrastructure for the new search stack is defined through Terraform in the govuk-infrastructure repository (except for Kubernetes platform deployment configuration which is managed in the same places as all other GOV.UK apps, including in govuk-helm-charts).
There are two separate top level Terraform deployments in the infrastructure repo:
- gcp-search-api-v2: Bootstraps the GCP project itself that all other resources live in (including IAM ownership, enabled APIs, quotas, and identity federation with Terraform Cloud to enable it to manage resources)
- search-api-v2: Manages the actual VAIS (and overall GCP) resources for each environment, applied through Terraform Cloud through a PR-based workflow
Monitoring & alerting
A Grafana monitoring dashboard for production tracks some of our core metrics. Sentry is set up to track application errors in Search API v2 including the sync process and API calls from frontend apps. We are aware of the following occasional errors which should not be considered critical and do not need intervention unless they occur consistently for a large number of users and don’t go away by themselves within a few minutes:
- Google::Cloud::DeadlineExceededError: A timeout occurred on the Google API
- Google::Cloud::InternalError: An internal error occurred on the Google API
- AMQ::Protocol::EmptyResponseError: RabbitMQ sent an unexpected response, possibly due to restarting (the listener will restart by itself in most cases)
Kibana on Logit can be used to query application logs as per all other GOV.UK apps.