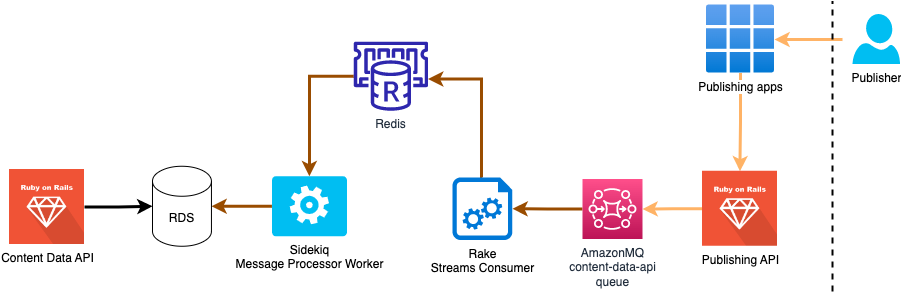
Content Data architecture
Content Data is a service that allows organisations to view performance and content metrics about GOV.UK pages they maintain, so that they can manage their content effectively over time. The data helps them decide what content to improve and prioritise.
Behind the scenes it is made up of:
- Content Data Admin, which manages the frontend of the service
- Content Data API, the data warehouse that stores the information used by Content Data Admin

Content Data Admin

This is a simple Rails app that provides the frontend service that users interact with. It has a database used solely for storing Signon users (required by the gds-sso gem), but mainly relies on metrics stored in Content Data API’s data warehouse.
Users of the app can:
- Search for content (filter by time period, title, URL, document type, organisation)
- View performance and content metrics for pages
- Export data to CSV
This can be accessed at https://content-data.publishing.service.gov.uk/content/.
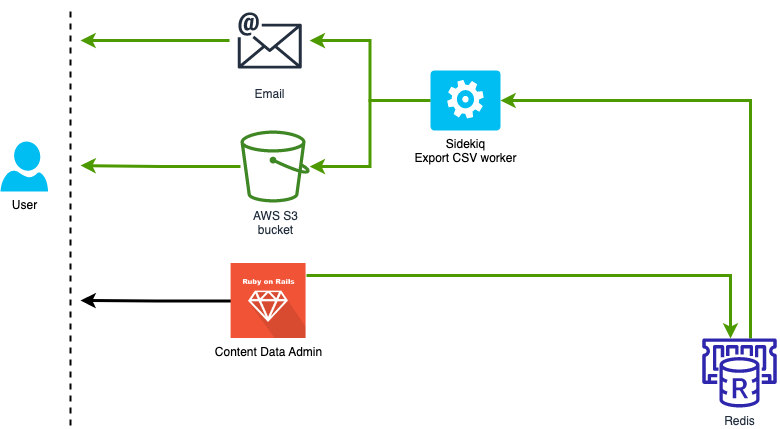
CSV Exporter
This is a feature that allows users to export search results and associated metrics to CSV. It uses a Sidekiq worker to generate the CSV in the background and stores it in an AWS S3 bucket. An email is then sent to the user which contains the downloadable link that is valid for 7 days. The expiry time is configured in the S3 bucket settings under Lifecycle configuration.
Content Data API
This is the data warehouse used by Content Data Admin where all the metrics are stored. The data is collected from various sources:
- Google Analytics (GA)
- Support API (specifically Feedback Explorer)
- Publishing API
It can be directly accessed at, e.g, https://content-data-api.publishing.service.gov.uk/api/v1/metrics.
Data sources
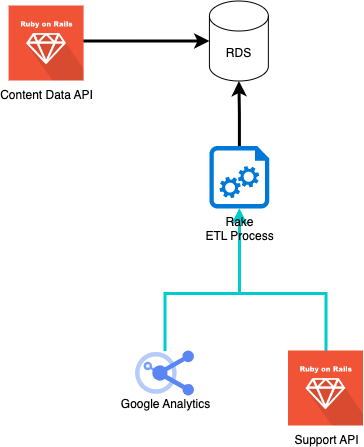
Google Analytics (GA)
Metrics collected from GA for individual GOV.UK pages include:
- Views and navigation
- User feedback
- Internal searches
This data is fed into content-data-api using the ETL process.
Support API (Feedback Explorer)
Feedback Explorer is a feature provided by the Support app, which collects information via forms on GOV.UK, for example:
- The GOV.UK contact form
- “Was this page useful?” form (at the bottom of every GOV.UK page)
These forms are managed and rendered by the Feedback app. When a user fills in the form on GOV.UK and submits the information, the anonymous data is then sent to Support API to be stored and processed further. Users of the Support app can then query the information in the Feedback Explorer.
There are two kinds of feedback:
- “Named contact feedback”: the public contact form at https://www.gov.uk/contact/govuk, which is the one technical means by which the public can start a two-way conversation with the government. It is rendered by Feedback, and form submissions are raised directly as new tickets in Zendesk, which are initially reviewed by User Support before being triaged elsewhere.
- “Anonymous feedback”: the little “is this page useful?” prompt at the end of each page. If users choose “No”, they’re invited to share their email and are then sent a SmartSurvey link where they can share further feedback. There’s also a “Report a problem with this page” button, which lets them describe what they were doing and what went wrong, but they’re not asked for an email address, so again it’s just one-way feedback.
All of the anonymous feedback is rendered by Feedback and collected via Support API. The data is then pulled into Content Data, where it can be reviewed by content folks / performance analysts.
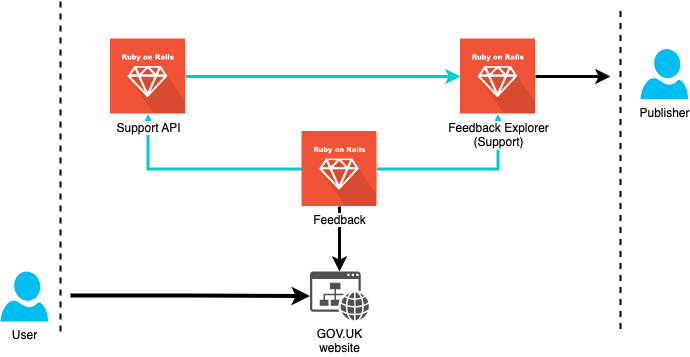
Content Data API only collects metrics on the number of feedback comments for pages on GOV.UK from Support API. This data is fed into its data warehouse using the Extract, Transform, Load (ETL) process.
Publishing API
Content Data API processes messages from the Publishing API in order to detect and track changes to content.
It stores information such as:
- Word count
- PDF count
- Reading time
- Information about editions and relationships with other documents
This data is fed into Content Data API via AmazonMQ and the Streams Processor.
How data is fed into the Content Data API warehouse
Data is fed directly into the data warehouse through two methods:
- The Extract, Transform, Load (ETL) Processor
- The Streams Processor
ETL Processor
Content Data API runs an ETL (Extract, Transform, Load) process daily as a rake task via a Kubernetes CronJob, which copies the data from GA and Support API into its data warehouse.
For more information see the What is the ETL process developer doc.
Streams Processor
This process is responsible for updating information about GOV.UK content from the Publishing API. Note that this data is different from the data collected from the nightly ETL process.
An overview of the process is as follows:
- Publishing API publishes messages about content changes to the AmazonMQ content-data-api queue
- Content Data API subscribes to this queue using a consumer process
- The consumer process then creates Sidekiq jobs (using Redis as a job management store) to ingest these messages via a rake task