content-data-api: ADR 009: Consume content items only from the publishing API
04-06-2018
Context
When we created the ETL pipeline we originally used the publishing API messages just to flag items as updated. Then we would fetch items from the content store overnight.
We now grow the Item dimension every time there is an update, instead of limiting it
to one record per day. Now that we do this, we rely on two sources of truth for this data:
the publishing API and the content store. We should not need to make requests to the content
store at all, because the content store is intended to support the frontend architecture, not ETL/analytics.
We are addressing this now because we want to change the data warehouse to store individual parts of guides and travel advice, and this is difficult to implement due to the complexity of the message processing.
Decision
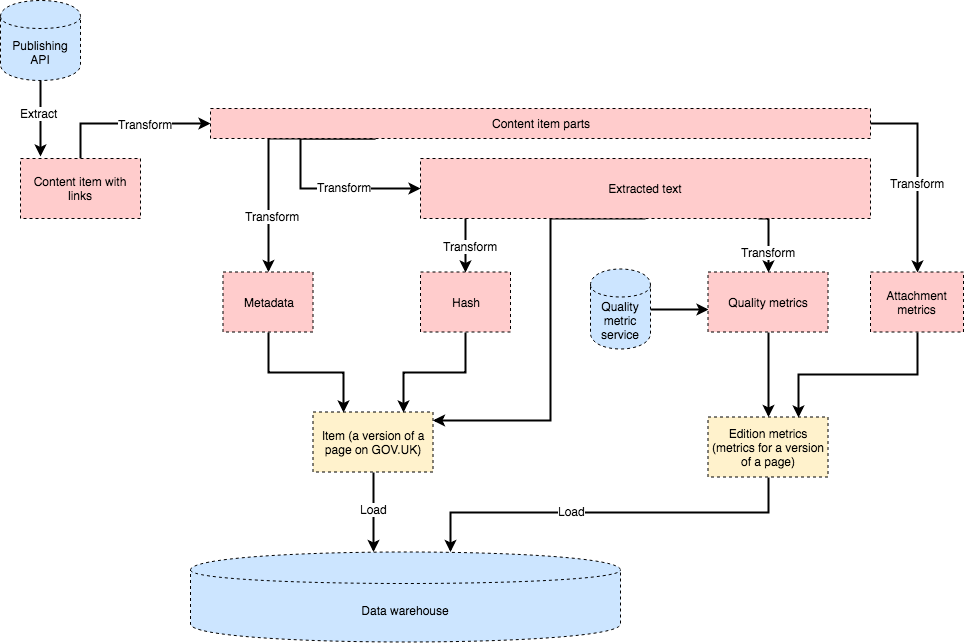
We will use the publishing API messages to extract all content, rather than issuing an additional request to the content store.
Data flow
We are refactoring the publishing API message hander, so that it first transforms a message into a ContentItem class, which stores all the information we need.
This is the input we use to present the content for that item, calculate a hash of that content, and (if neccessary) calculate quality metrics for that content. We have decided to do all this processing synchronously for the time being so the pipeline is more predictable and easy to debug.
Growing the item dimension
We subscribe to these kinds of updates from the publishing API:
- major
- minor
- links
- republish
- unpublish
A new item record is created if:
- we've never seen that content item before
- the content hash changes
- the links change (if links appear in a different order they should still be considered the same)
Otherwise we don't insert new records.
When creating a new item we "promote" it by setting latest=false on the existing latest item with that content ID, and setting latest=true on the new item.
Impact of multi-part items
For a multi-part item, we will transform a single message into multiple items, each with a unique base path but a shared content ID.
The base path of a part-item is the base_path attribute of the publishing API content item plus the slug of the part in the details hash.
When we grow the dimension, we mark all parts with the same content_id with latest=false, and create new item records for all the part items from the new message.
Benefits:
- We can implement multi-part documents very easily
- The data warehouse doesn't depend on frontend infrastructure.
Status
Accepted.