Architectural deep-dive of GOV.UK
We can cover a lot of GOV.UK architecture by asking ourselves three questions:
- What happens when a user visits a page on GOV.UK?
- What happens when a publisher hits ‘Publish’?
- What happens when a developer deploys a change to an application?
Refer to the architectural summary of GOV.UK for a shorter summary of GOV.UK architecture.
What happens when a user visits a page on GOV.UK?
DNS
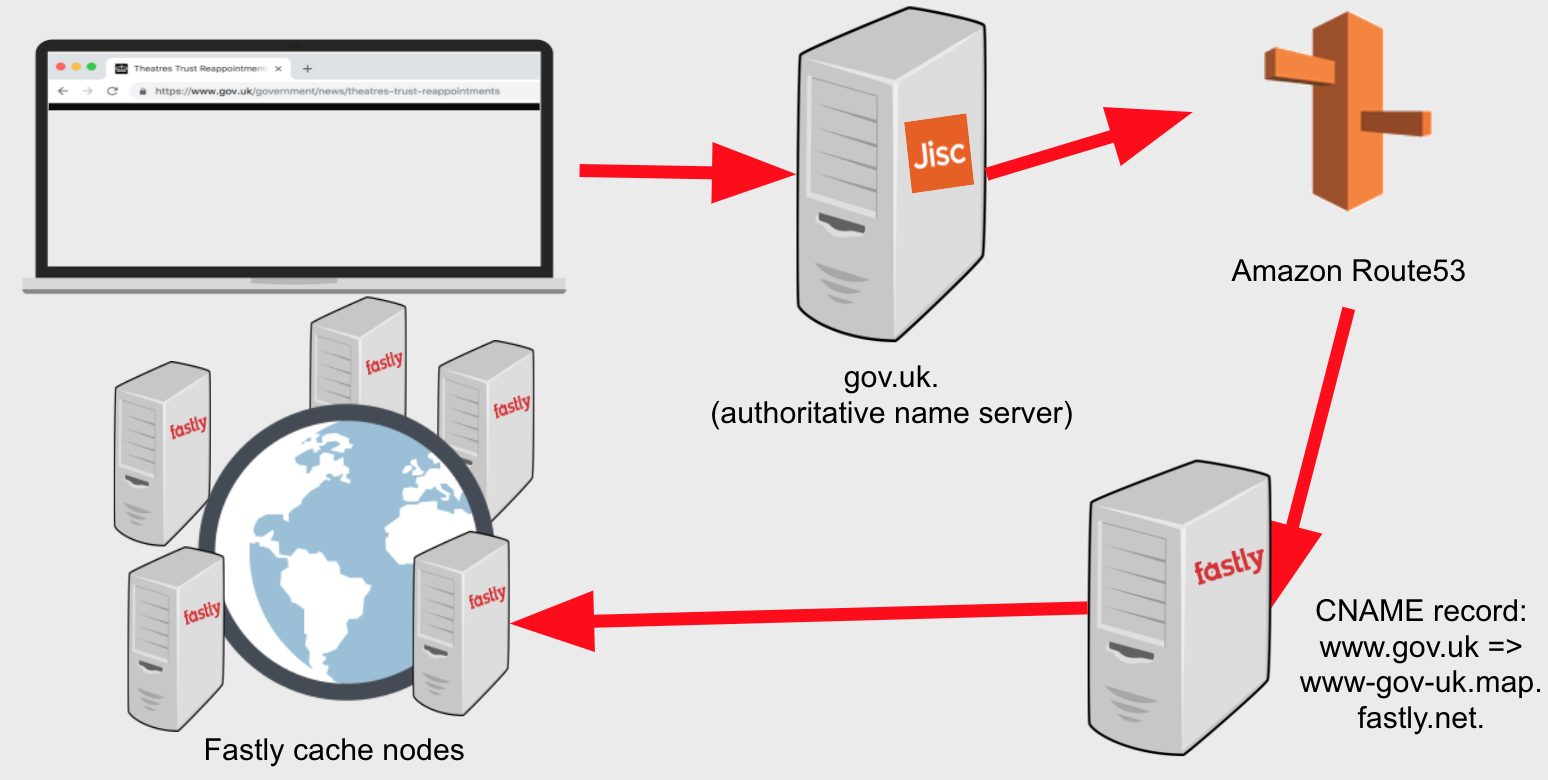
The browser queries a local DNS server to turn the domain name into an IP address. The local DNS server might be able to answer immediately from its cache. If not, it will query the authoritative name servers for the domain.
gov.uk. is a country-code second-level domain or ccSLD (like co.uk.) and its
authoritative servers are hosted by Jisc. Unusually for a ccSLD, gov.uk is
also a website, and hosts the redirect from gov.uk to www.gov.uk. The records
for these two domains are within the gov.uk second-level zone hosted by Jisc.
www.gov.uk is a CNAME record which ultimately points to www-gov-uk.map.fastly.net.
The fastly.net domain name is hosted by special nameservers at the Fastly content
delivery network, which aim to respond with the IP address of the Fastly cache node
which is “closest” to the user. Read more about Fastly in the next section, or
read more about gov.uk DNS.
CDN and caching
GOV.UK uses the Fastly CDN to handle the majority of requests, which - as well as reducing load on GOV.UK (‘origin’) by around 70% - provides ‘edge nodes’ (servers) that are closer to our end users (particularly those outside the UK).
Fastly uses has a default cache time of 1 hour. (Read “Our content delivery network” for more information). If Fastly doesn’t have a page in its cache, it fetches the page from origin.
Caches can be purged, which tells Fastly to soft-purge (i.e. only remove the cached version once it has received the new version from origin).
Failover
If a Fastly request to origin returns a 5xx response, Fastly will request content from the mirror, which is static HTML hosted in an S3 bucket on AWS. The contents of the mirror are updated daily via the govuk-mirror crawler, which recursively crawls GOV.UK URLs from a message queue, visiting the pages and saving the output to disk.
- Read more about fallback to the static mirrors and how the mirrors are populated.
- Read more about how errors are handled on GOV.UK.
Routing on the CDN
Fastly also routes assets (e.g. assets.publishing.service.gov.uk) directly to the S3 bucket.
Fastly is also used for the redirection from gov.uk to
www.gov.uk, which is configured via govuk-fastly.
Other redirects that happen at the Fastly level include bouncer: a GOV.UK application responsible for redirecting traffic from old pre-GOV.UK websites. This is configured via transition. Read Transition architecture for more detail.
Routing on GOV.UK
graph LR;
A[Fastly]-->B[Router Load Balancer];
B[Router Load Balancer]-->C[Router nginx];
C[Router nginx]-->D[Router];
D[Router]-->E[Backend];
Some requests make it through the CDN and cache layers to ‘origin’. Origin is Router’s load balancer. Router is a reverse proxy app written in Go and loads all routes into memory from from the content store Postgres database.
Routes have different handlers. Routes marked as gone return a 410 Gone
response. Routes marked as redirect serve a 301 Moved Permanently
response. These handlers are useful for when content is deleted or
superseded. Most publishing apps provide a way of deleting or redirecting
their content, but it’s worth noting the short-url-manager app, whose
sole purpose is to create special redirect routes to allow the creation
of short, memorable URLs that redirect to longer URLs, often as part of a
media campaign.
Routes with a backend handler are routed to the relevant rendering app,
based on the backend_id of the route, which is derived from the
rendering_app field in the corresponding content item in the Content
Store - we’ll cover this later. For example, if the route has a
backend_id of frontend, it will forward the request to the frontend
application.
Rendering
Once Router has forwarded the request to the right rendering app, the
rendering app itself has to do some routing. Most GOV.UK front-end apps are
built in Rails, which means typically there is a routes.rb file that
maps the route to a controller. The controller takes the URL path and any
parameters and decides how to render the page.
Many pages require the application to make a request to the Content Store to retrieve the corresponding content. Some pages are associated with collections of content, rather than simply one content item. If it is a static collection, such as a homepage which references several news stories, then this remains just one content item that has been expanded via “link expansion” (which we’ll cover later) to ‘include’ the other content items within it. If it is a dynamic collection, such as a search results page, then content items are retrieved via the search-api.
Static assets
Whilst views can be any arbitrary HTML, GOV.UK pages are typically constructed from components defined in govuk_publishing_components, set in a standard page template (header, footer, JavaScript and CSS) also defined in govuk_publishing_components. For more details, read about the GOV.UK Frontend architecture.
Static JS/CSS is delivered over https://assets.publishing.service.gov.uk. Custom assets, such as images, are delivered over the same domain and uploaded by content designers via asset-manager. Under the hood, all of these assets live in an AWS S3 bucket; read “Assets: how they work”.
Summary
The request is resolved through DNS, more often than not hitting the CDN. Some requests make it through to origin, where they’re routed to the pod running the (usually Rails-based) rendering application that knows how to handle the request.
What happens when someone hits ‘Publish’?
Draft and live stacks
Everything you’ve just read about in the first section exists in two stacks: draft and live. Everything that runs in the live stack also runs in the draft stack, in order to have a way of previewing content in a non-public-facing way. However, the draft stack also has applications that run the publishing apps.
Applications shouldn’t know what stack they’re in - they’re simply configured to talk to other applications in their stack.
The live stack entry point is the ‘router’ app. You can swap www for
www-origin to bypass Fastly and view the live stack at origin. This is
only available to office IPs / VPN, and to Fastly IP addresses (configured in
govuk-fastly).
The draft stack entry point is authenticating-proxy, which sits in front of ‘router’.
graph LR;
A[Authenticating Proxy Load Balancer]-->B[Authenticating Proxy nginx];
B[Authenticating Proxy nginx]-->C[Authenticating Proxy];
C[Authenticating Proxy]-->D[Draft Router nginx];
D[Draft Router nginx]-->E[Draft Router];
E[Draft Router]-->F[Draft backend];
You can swap www for draft-origin to view the draft stack at
origin. The draft stack is not IP-restricted, as we need to be able to share
links to be reviewed (“2i’d”) or fact-checked by non-Government departments.
It is, however, only visible to users who have been verified through
Authenticating Proxy, by signing into signon (an authentication and
authorisation portal) or by providing a valid auth_bypass_id (as a URI
parameter or session cookie). Read more about previews in “How the draft stack works”.
Signon doubles up as an authorisation platform, as it associates users with arbitrary permissions, so a publishing app can query if the current user has the necessary permissions to perform a given action, such as publishing content.
Publishing API vs Content Store
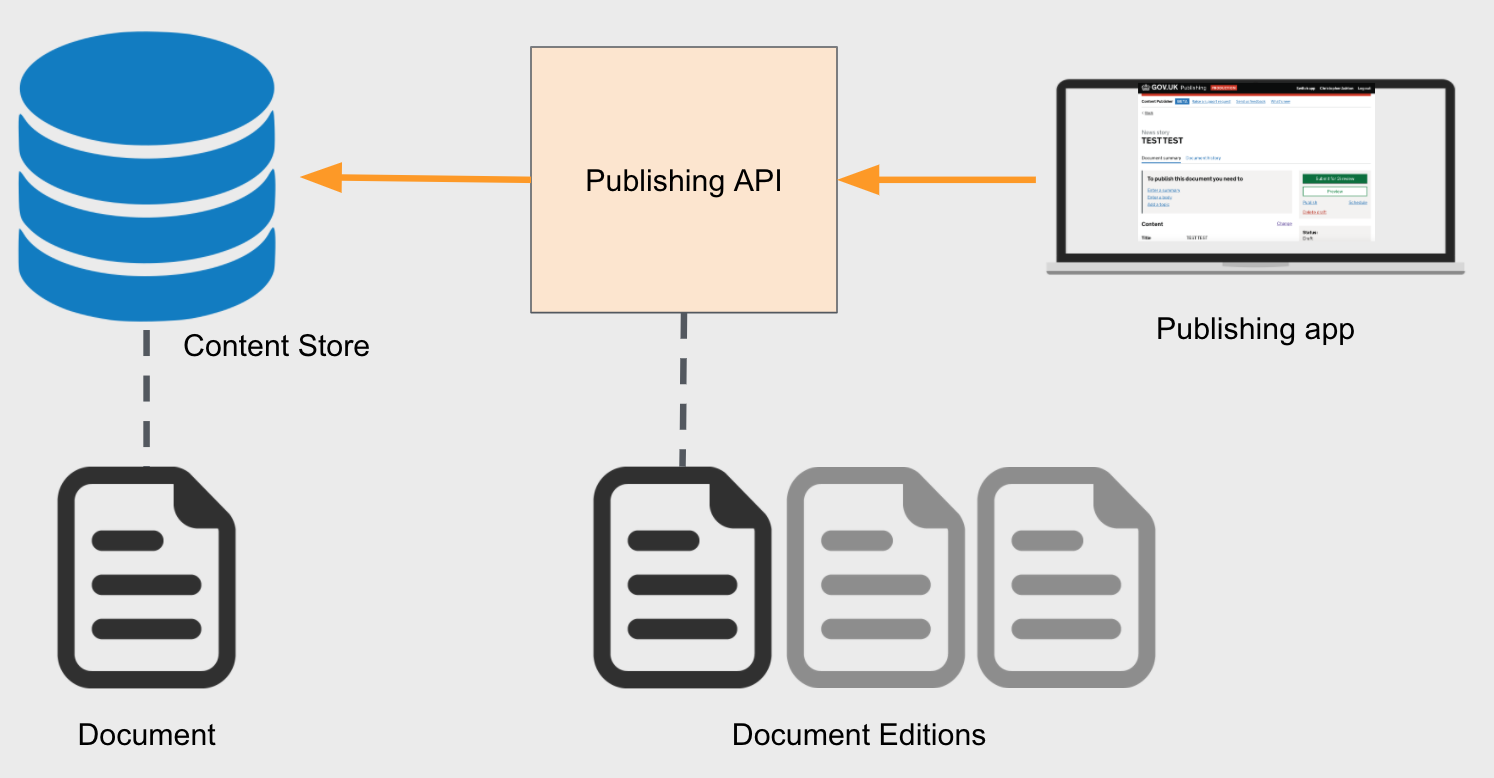
At this point it’s probably worth summarising what “content” is. Almost every piece of content on GOV.UK lives in a database called “content-store”, which stores only the latest “edition” of that content. Internally the content is referred to as a “document”, even if it is not itself a document. Content is retrieved via the “Content API”, which lives in the content-store repo.
Content is published to the Content Store via the Publishing API, which
stores all of the editions of the document, and performs validation checks
whenever it receives a new edition. Every piece of content has a schema_name
corresponding to a particular JSON schema defined in the content schemas in Publishing Api.
Most backend apps have their own databases modelling documents in their own
way; at the point of sending the document to Publishing API, they transform the
document to a JSON payload conforming to the appropriate schema.
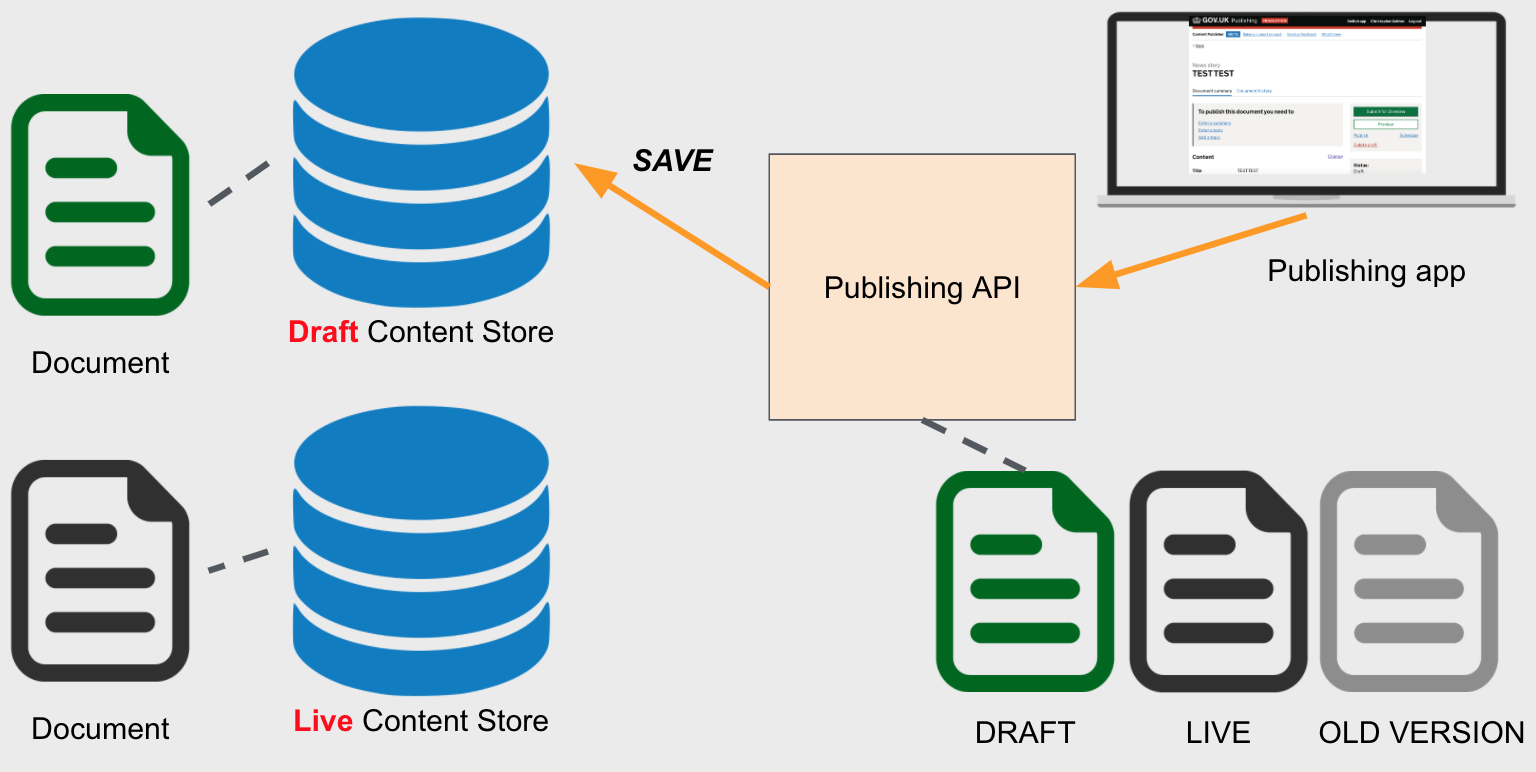
When a new edition is sent to Publishing API, it is automatically published to the draft Content Store, replacing whatever contents existed for that document beforehand. An edition must be explicitly published for it to go to the live Content Store, where it becomes visible to the outside world.
Link expansion, mentioned in Rendering is the process of joining related content items (such as the title and details of a document’s parent, used for navigational breadcrumbs) into a single JSON payload, so that rendering apps don’t need to handle the complexity of pulling all of that data together manually. Link expansion happens in Publishing API at the point of sending an edition downstream to the Content Store.
Downstream Sidekiq background processing triggered by publishing
The Publishing API could update the Content Store directly, but the scale of GOV.UK means we’re safer offloading that call to a background process to be processed when resources become available. In addition, when we publish a new edition, we often want to trigger some other actions as a result. For example, we want to send an email to anyone subscribed to that content.
We use Sidekiq to manage the background processing. When each Sidekiq process is evaluated, a message is put onto a RabbitMQ queue.
The RabbitMQ cluster used by publishing-api is managed by AWS, via their AmazonMQ service.
RabbitMQ is a message broker: when a message is broadcast to a RabbitMQ exchange, it forwards the message to its consumers. These consumers retrieve the content item and do something in response, such as:
- Send emails to users subscribed to that content. (The
exceptions to this are
travel-advice&specialist-publisher, which communicate directly with email-alert-api to ensure emails go out immediately)
Sidekiq queues: high and low priority
Updating one content item often requires updating other pieces of content. For example, if a content item’s title has been changed, then content items which refer to that content item will need to be updated to use the new title. Sometimes a single change can trigger changes in thousands of items.
Putting both the directly changed and indirectly changed content items on the same queue would mean it would take a long time to see the changes in a document you’ve edited. Generally, it is less important to see a quick change to the indirectly changed content than it is to see a change in the directly changed content items. Therefore we have a concept of ‘high’ and ‘low’ priority queues.
The main content item is processed in the high priority queue. Exactly the same things happen to the low priority content items as the high priority content items; it just tends to take longer as there are more items to process.
The process for finding the content items affected by a content change is
known as dependency resolution. Content items can be associated with
other content items in a number of ways. For example, you may provide an
array of organisation IDs in your payload
when sending to Publishing API, to indicate that those organisations are
responsible for the content (this is stored on the content item in content
store as links.organisations).
Content can also be tagged to taxonomies, which are used to describe where
in the site hierarchy the content sits. These are stored on the content item
as links.taxons. Some apps have their own interface for tagging, or you can
tag content independently using content-tagger.
Summary
The publishing app uses the Publishing API to create and synchronise a new edition of a document, which consolidates related content items into it prior to sending to Content Store. All affected content items are added to a publishing queue, which triggers downstream actions such as cache clearing and email alerts.
What happens when a developer deploys a change to an application?
Environments
There is a copy of the live and draft stacks in each of the following environments:
- Production
- Staging
- Integration
Nightly cronjobs copy data from Production to Staging and from Staging to Integration. This is because:
- this gives us automated restore testing, to prove that we can actually restore from production backups
- we don’t yet have example datasets suitable for development and testing purposes
- most of the data is public
Some data is removed or redacted in the staging environment so that we don’t copy it to the integration environment, such as:
- email addresses, for example of subscribers to topic change notifications
- draft content that has yet to be published on the public website